RelA — Reliability Autohealer — small prototype designed to study how reliability decisions behave under load.
In an earlier post, I described the motivation and the question behind RelA. This post focuses on what the system actually revealed once the feedback loop was made explicit.
The goal is to make reliability decisions observable, and to make it observable can the components of the system be separated. This ultimately poses the question -
What changes when reliability decisions move out of the request path and into a control plane?
RelA models a control loop end-to-end on a machine: metrics → policy evaluation → action → verification, with an explicit audit trail.
Why this problem exists (even when everything is 99% healthy)
In distributed systems, average latency is a vanity metric. Reliability is shaped by tails and tail behavior is what breaks user journeys.
In a fan-out architecture, a single user request fans out to 20 downstream calls and each call succeeds 99% of the time, the user journey does not succeed 99% of the time:
Closing this gap requires structural mitigations such as hedging, load shedding, timeouts, queue controls, etc. These techniques are necessary and they work — but under saturation they can conflict with each other.
RelA was built to study that tension. It is essentially a sandbox for that world: create congestion, observe tails, apply mitigation and see second-order effects.
Architecture - Policy outside the hot path
Most production stacks embed reliability logic (timeouts, retries, hedging) inside application SDKs.
That works-until the service is under stress. Then the application is doing 2 jobs -
- serving traffic
- Making decisions on what to do about the traffic.
This coupling creates a classic failure mode: Priority Inversion - a busy system spends its last compute cycles trying to decide how to save itself.
To mitigate this, in RelA the decision engine is moved out of the hot path and into a control plane inspired by the control-plane/data-plane split used in Software-Defined Networking (SDN).
-
Data Plane (
main.py) A FastAPI service that processes requests, handles/work. It is stateless and acts only on externally supplied flags -hedge_enabled,degraded_mode,shed_bronze. -
Control Plane (
agent.py) A Python loop that polls Prometheus metrics, evaluates policy, and pushes decisions to the application. -
Source of truth (
config_server.py) A tiny config service that holds the current global state. The service polls it like a sidecar.
This separates the cycle of deployment from the cycle of control (changing decision logic). It also makes failure modes easier to reason about: you can inspect the decision loop independently of request handling.
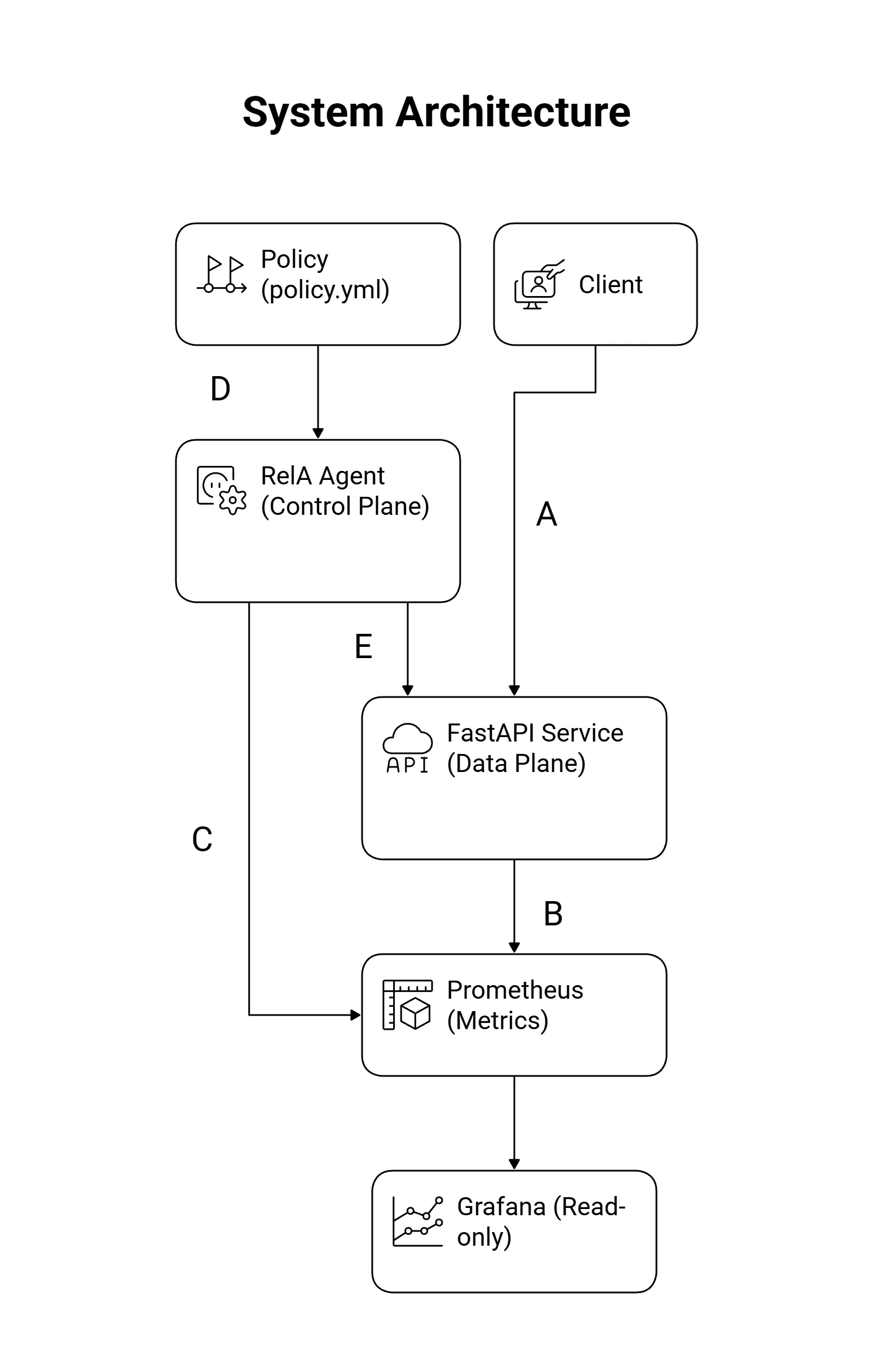
Reliability decisions are evaluated outside the service and asserted back as small control flags.
Design constraints the system revealed
1. A controller acts on sampled reality
Control loops never react to the real world. They react to a measured projection of it.
In RelA, the decision loop is bounded by 4 independent clocks:
- Prometheus scrape cadence
- query windowing semantics
- controller evaluation interval (2s)
- application-side config polling interval (2s)
Those 4 clocks exist in every real system for - metric production & scrape, aggregation/windowing, decision evaluation and lastly actuation/config propagation. They define the earliest possible moment at which a change in system behavior can be detected, reasoned about, and acted upon. No amount of fast logic can overcome that bound.
This is where controllers become correct but late.
A latency spike that begins and ends inside a window may be invisible. A spike that has already subsided may still influence decisions for multiple cycles.
This is not a bug — it is the cost of sampling.
Production systems account for this by introducing intentional inertia:
- consecutive breaches to enter a mode
- consecutive clears to exit
- minimum dwell times to prevent flapping
RelA makes this constraint explicit rather than implicit. It changes ownership, coupling and blast radius of those clocks. The feedback loop is centralized, explicit, and reversible, instead of being scattered across request paths, SDK logic, and platform defaults.
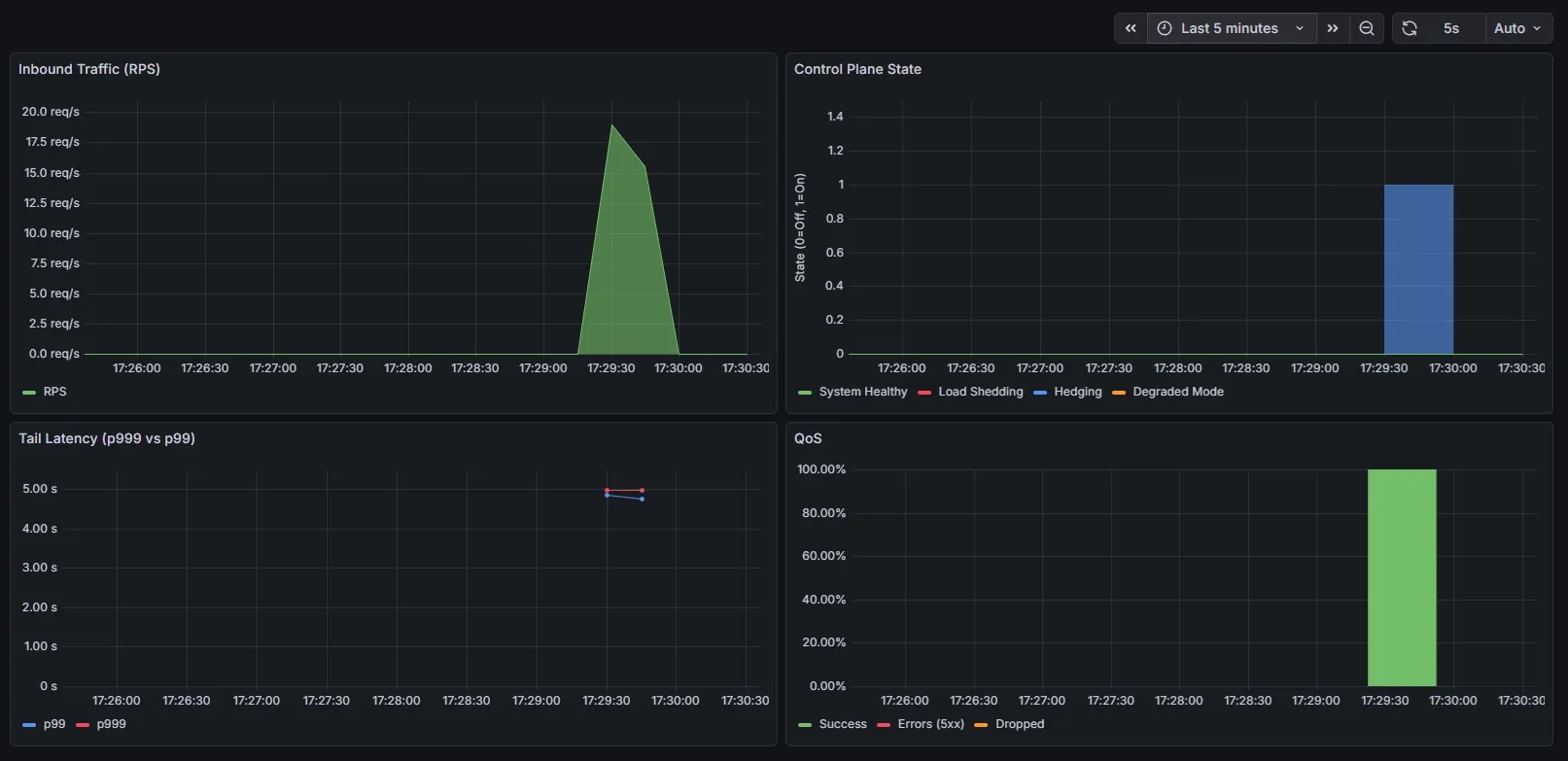
The controller transitions modes only after sampled signals converge, not at the moment conditions change.
2. Tail mitigation can self-amplify under saturation
When tail latency rises, the instinctive response is to enable hedging.
In RelA, hedging improves tail behavior by spending additional work on slow requests. That works—until the system is already resource-bound.
Under saturation, spending more work to reduce latency can be the wrong move.
This is a broader reliability failure mode: mechanisms that are correct in isolation can become destructive when combined without coordination.
RelA exposes this by forcing explicit mode arbitration in policy:
- survival actions dominate performance actions
- only one mitigation mode is active at a time
The controller evaluates policies in priority order and exits on the first match:
for actionin policy.get("actions", []):
if triggers.intersection(breaches):
target_action = action["name"]
break #selects the first applicable action and exits
This single break matters.
It enforces mutual exclusion between:
- survival mode (shedding to protect capacity)
- performance mode (hedging to reduce tails)
The system is never allowed to optimize latency while it is failing capacity. That trade is resolved structurally, not heuristically.
The result is predictability. The system enters a clearly defined mode and behaves consistently until conditions change.
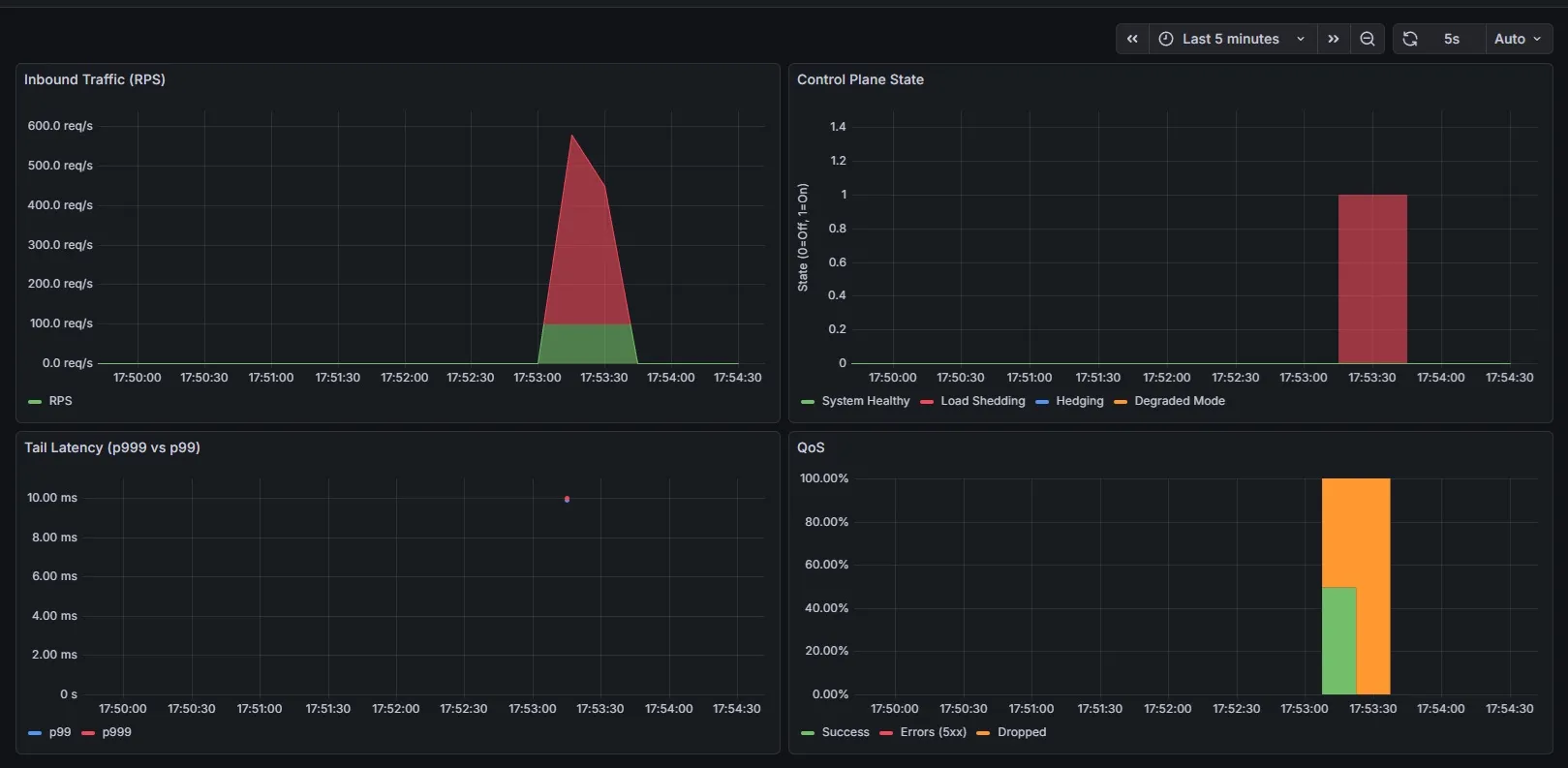 Under saturation, the controller suppresses tail optimizations and enters a single, capacity-preserving mode
Under saturation, the controller suppresses tail optimizations and enters a single, capacity-preserving mode
3. QoS as a product decision
Random shedding treats all requests equally. In practice, systems often care about which requests succeed.
RelA allows business context (for example, user tier) to participate in control decisions. This shifts the definition of success from requests processed to value preserved.
- Gold (higher-tier)- bypass shedding, traffic continues through normal path
- Bronze (lower tier)- dropped duting surviaval mode (fast-fail with 503), traffic degrades first
From a CAP perspective, this accepts lower consistency to preserve availability for the partition that matters most.
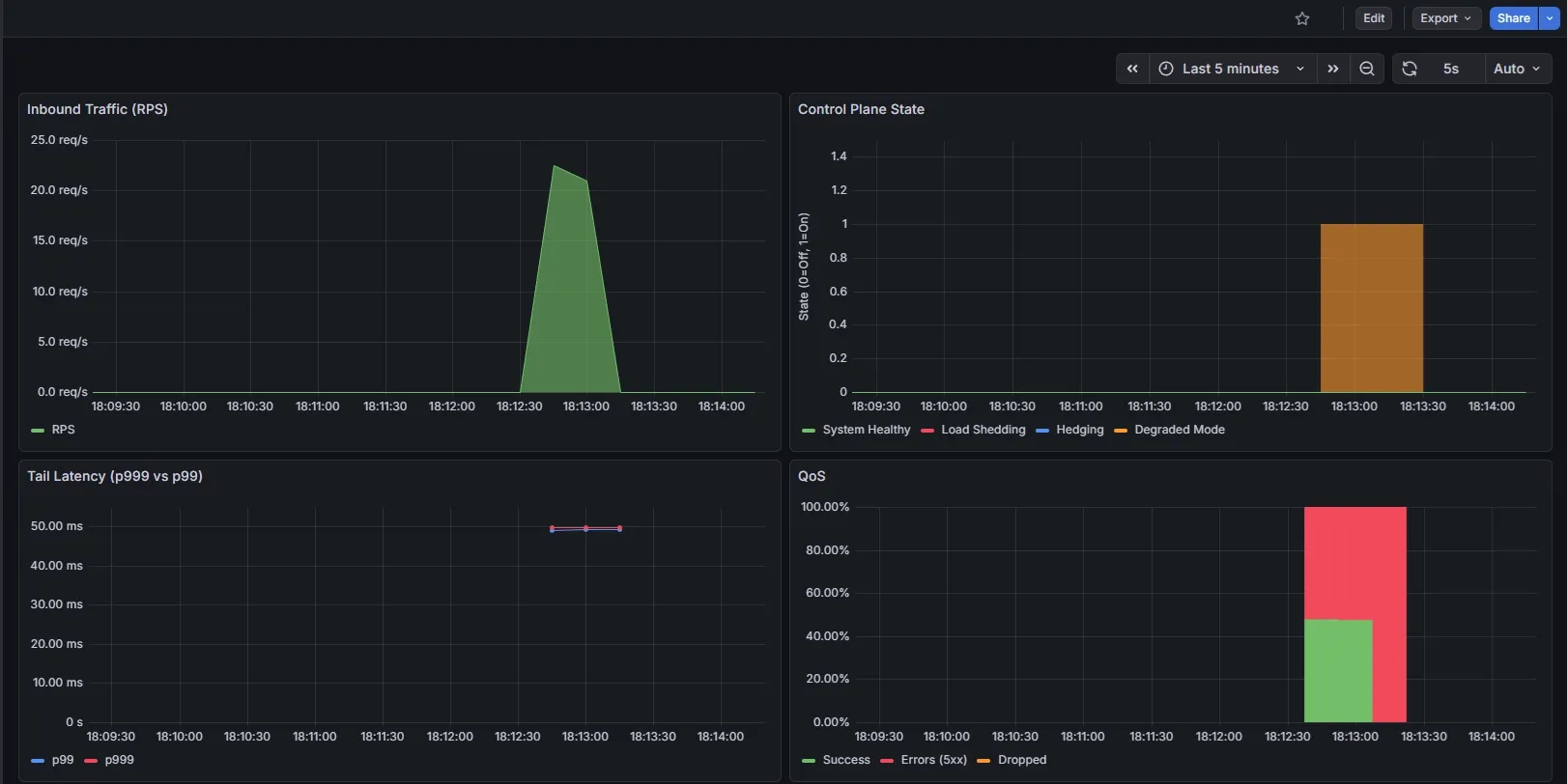
Reliability outcomes are asymmetric by design, preserving value rather than fairness during failure.
Evidence: Decision and outcome alignment
RelA treats policy-driven drops as first-class outcomes, not failures. Errors and drops are intentionally tracked separately to preserve decision semantics in the control loop.
Agent logs below show deterministic mode selection aligned with observed signals and policy priority. RPS surge threshold is set at 100 req/s.
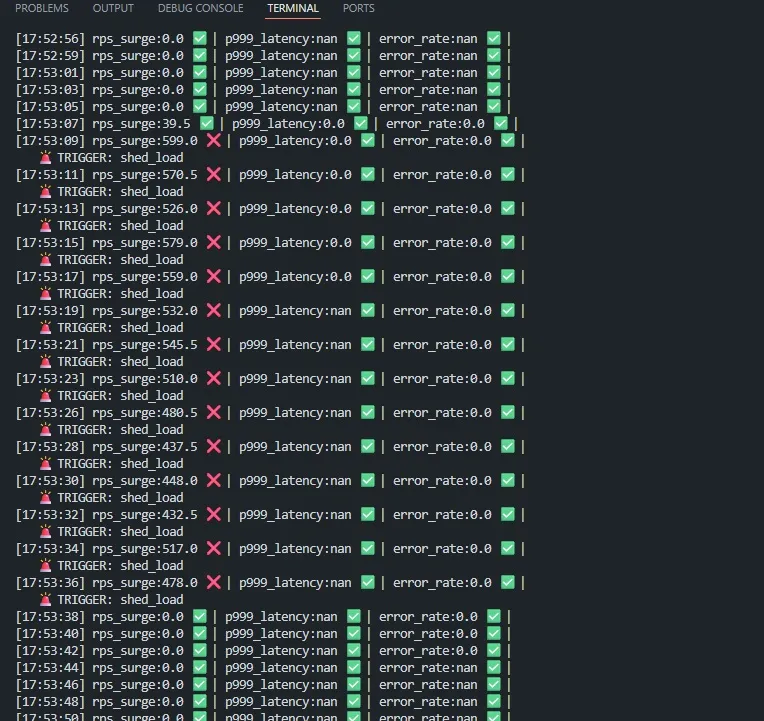

Application-level behavior reflects control decisions directly, making reliability trade-offs visible at the boundary.
What to harden if this were production
RelA is intentionally small, but the constraints it exposes are the same ones that surface at scale. Hardening would focus less on adding features and more on controlling failure modes:
1. Control-plane availability and scope: The controller can’t be a single point of failure. In production this evolves into:
- HA - per-pod, per-zone agents
- Leader election - for shared policy ownership
- Sharded controllers - decisions apply to a shard, not the entire fleet
In a nutshell, the goal is not global coordination, but local survivability when the parts of the system already degraded.
2. Guardrails on autonomous action: Autonomy needs limits. Without guardrails, automation quietly becomes new source of instability.
- Cooldowns - minimum dwell time per mode
- Max durations - upper bounds on how long a mitigation can remain active
- Exit conditions - explicite exit criteria, not just threshold recovery.
3. Auditability as a first-class concern: Persistent logs should be tied to metric values and chosen actions.
At scale this means:
- persistent decision logs (metric → threshold → action)
- correlation with request traces or incident timelines
- human-readable explanations for why a mode was entered or exited
4. Progressive rollout of policy changes: progressive rollout of policy changes, with override paths to limit blast radius by service, tier or region.
Retrospective
2 patterns stood out once the control loop became observable:
1. Remediation speed is bounded by signal resolution - You cannot correct in seconds what you measure in minutes.
Scrape intervals, query windows, evaluation cadence, and config propagation together define the minimum achievable recovery time.
If the signal arrives late, the decision will be correct — and still wrong for the moment.
This constraint exists in every production system, whether acknowledged or not.
2. Control must be level-triggered, not edge-triggered - Desired state must be continuously asserted to prevent drift.
RelA continuously asserts desired state based on current conditions:
- mitigations stay active while breaches persist
- mitigations exit only when conditions are demonstrably stable
This prevents configuration drift and avoids half-healed systems where automation fired once and never fully recovered.
Together, these reinforced a simple idea: reliability failures are often decision-structure problems, not mechanism gaps.
Final note on scope
RelA is intentionally minimal. It is not a production system, and it does not claim absolute performance results. Its value lies in surfacing behaviors that remain consistent across scale.
The same patterns appear in much larger systems—only with higher cost.
Notes on numbers: the latencies and recovery times below come from local runs on my machine and will vary with hardware and load shape. The point is the shape of the behavior and the design constraints behind it.